Traditional RAG Limitations
Traditional retrieval-augmented generation (RAG) often forces a choice between dense vector search (semantic meaning) and sparse keyword search (term frequency).
Anatypical unpacks every document into its entities and relationships, then connects them across everything your organization knows.
Anatypical deploys into your infrastructure with full configurability, no external dependencies, and complete source traceability across every query and generation.
Our platform offers enhanced Hybrid GraphRAG capabilities, Knowledge Graph creation, and AI-memory management within deployable architecture with complete configurability.
Traditional retrieval-augmented generation (RAG) often forces a choice between dense vector search (semantic meaning) and sparse keyword search (term frequency).
GraphRAG utilizes Entity-Relationship extraction to create navigable Knowledge Graphs, but lacks scalability and requires defined ontologies.
Our Answer
Our Hybrid GraphRAG system utilizes each of these techniques while using an Open-Ontology method by clustering data and traversing through entity matching, semantic similarity, and relationship compression.

How We Build It
Accepts over 50+ types of file extensions to be ingested into a single searchable data plane.
Allows for plugins such as video and audio transcribers to be utilized for multimodal inputs.
Pull directly from data sources such as Outlook, Teams, and Google Drive.
Does not rely on any single provider for LLMs. Configure any commercial or open-source model.
Long-term projects, ongoing investigations, data-intensive work with integrations, isolated memory, and entity-relationship detection, unlike one-off prompts that reset every session.
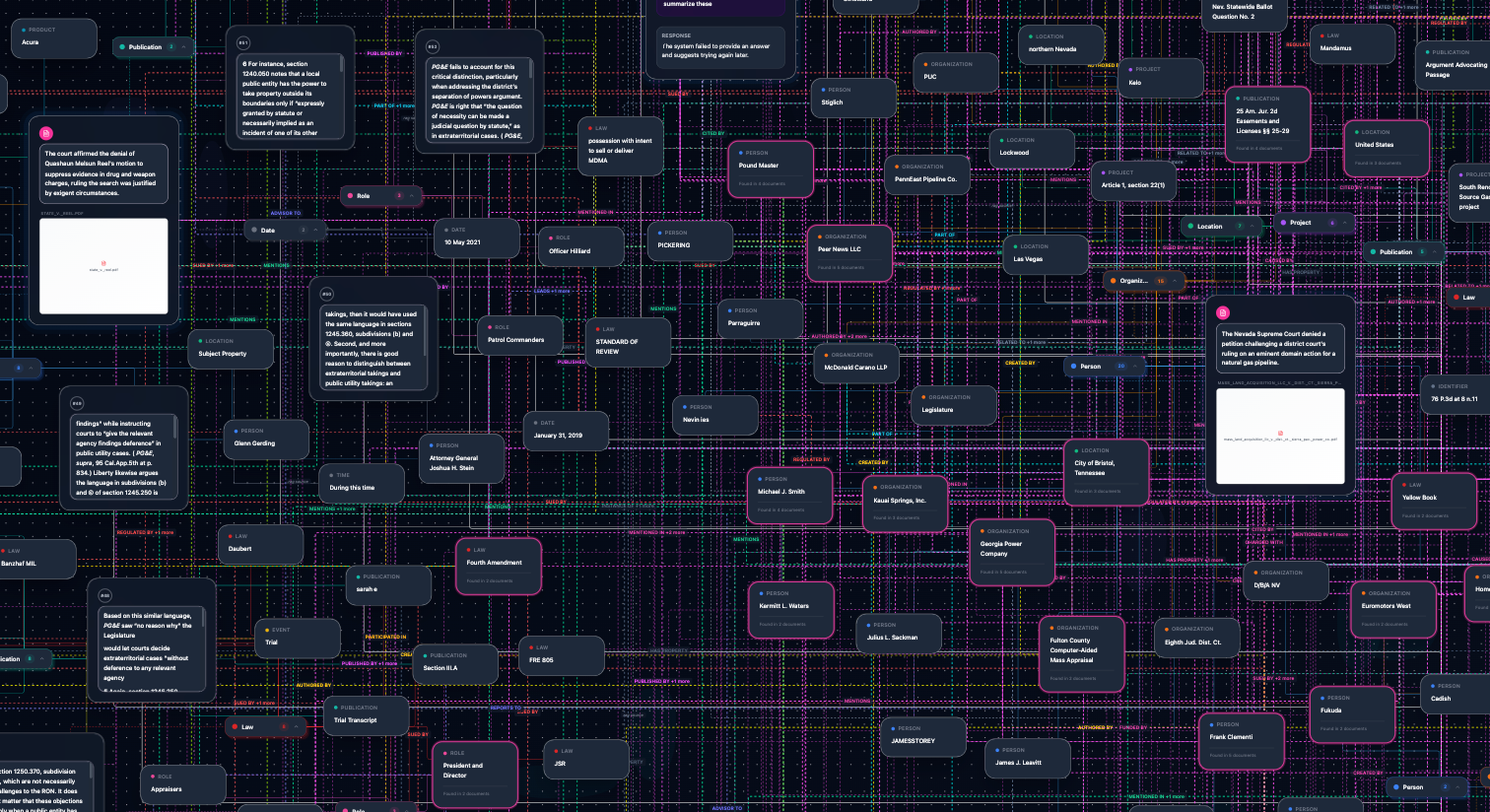
Each generation is connected to the data points retrieved from the Knowledge Graph and Vector Space along with model perplexity, BM25, and cosine similarity scores.
Unlike ChatGPT or Claude, S.P.I.D.R. is data-centric. Every generation includes a Contextual Graph with full memory provenance control.
Multiple users can work concurrently within the same "Space" to build and analyze data together.
The UI is built as a flexible canvas for intuitive interaction with your data and knowledge graphs.
Platform offers configuration parameters for LLM and retrieval. System orchestrated through k8s, auto-scales through KEDA.
Users can view and edit which previous responses are linked to the current generation for full control on memory inputs.